I. Adjacency matrices and paths in graphs¶
I.1. Definitions (Review of CSE 102)¶
Throughout this Notebook a graph $G$ of size $n\geq 1$ is given by $(V,E)$ where:
- $V=\{v_1,\dots,v_n\}$ is a finite set of vertices;
- $E\subset V^2$ is a set of edges.
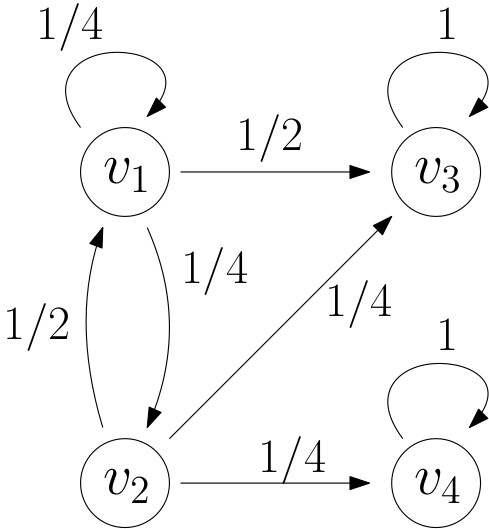
The following is a graphical representation of the graph with
- $V=\{v_1,v_2,v_3,v_4\}$
- $E=\{(v_1,v_2),(v_2,v_2),(v_2,v_3),(v_3,v_4),(v_4,v_4)\}$
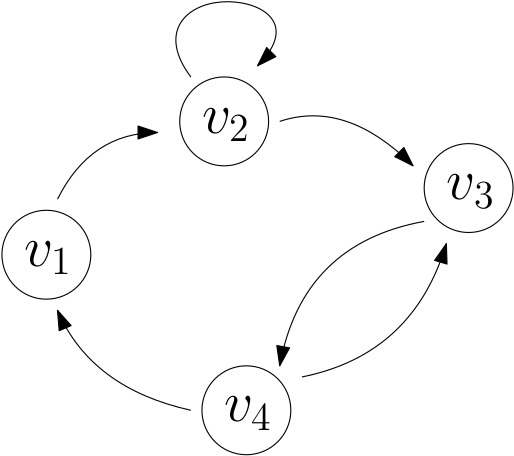
In the above example, $$ A_G= \begin{pmatrix} 0 & 1 & 0 & 0\\ 0 & 1 & 1 & 0\\ 0 & 0 & 0 & 1\\ 1 & 0 & 1 & 0\\ \end{pmatrix} $$
I.2. Powers of the adjacency matrix¶
We will continuously use the following property, as it is the one that makes the introduction of adjacency matrices relevant.
Proof of Proposition 1.
We do the proof in the case $k=2$, the general case follows by induction. Write $A_G=(a_{i,j})_{1\leq i,j\leq n}$. Then by definition of matrix product:
$$
(A_G^n)_{i,j}=a_{i,1}a_{1,j}+a_{i,2}a_{2,j}+\dots + a_{i,n}a_{n,j}.
$$
Consider a term $a_{i,\ell}a_{\ell,j}$ in the above sum. This term is zero unless $a_{i,\ell}=a_{\ell,j}=1$. The latter means that we have a path of length two $v_i \to v_\ell\to v_j$. In other words
$$
a_{i,\ell}a_{\ell,j}=
\begin{cases}
1 \text{ if there is a path of length $2$ from $v_i$ to $v_j$, through $v_\ell$}
,\\
0 \text{ otherwise}
\end{cases}.
$$
By summing over $\ell$ we obtain the proposition in the case $k=2$.
End of proof.